Time Complexities of Table Joins
If both tables are sorted, the sort-merge algorithm performs the best.

There are three famous join algorithms for relational tables. They are nested join, sort-merge join, and hash join. In this article, we will compare those algorithms in terms of time complexity. Note that we will assume there are only a negligible number of duplicate values in both joining columns. That is because if all those values are the same, the number of rows of the output table will be MN, which means any algorithm cannot do better than O(MN).
Nested Join - O(MN)
This is the simplest algorithm. Simply loop through the smaller table for each row in the larger table to find the matching rows.

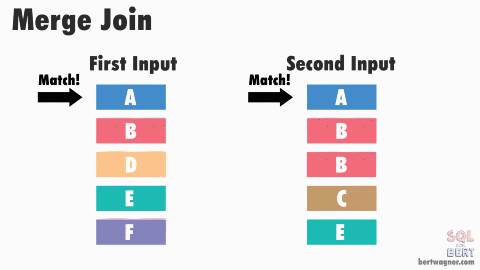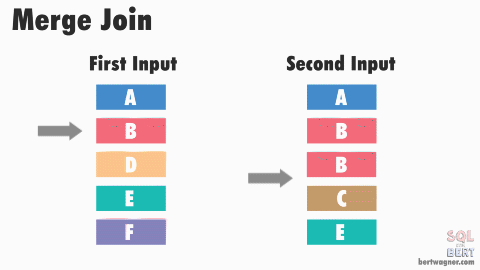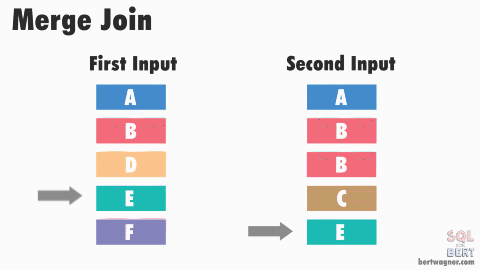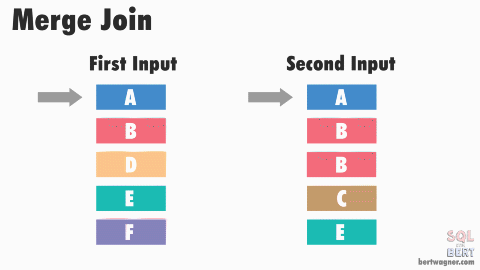
Sort-Merge Join - O(M + N)
If both joining columns are sorted (or indexed by a B+ tree-like structure), the sort-merge join gives you the time complexity of O(M+N).

Hash Join - O(M + N)
You can join two tables in O(M + N) even if they are not sorted or indexed at the additional space cost of O(N).

Comparison

Reference